nltk 토큰화
import nltk
sentence = "Hi . This is Tom . I have many cars ."
sentence = sentence.lower()
tokens = nltk.word_tokenize(sentence)
# 토근화
print(tokens)
text = nltk.Text(tokens)
# 토큰 다시 텍스트화
print(text)
print(len(text.tokens))
print(len(set(text.tokens)))
for token in text.vocab():
print(token, text.vocab()[token])
# text.vocab[token]에 출현수 저장됨
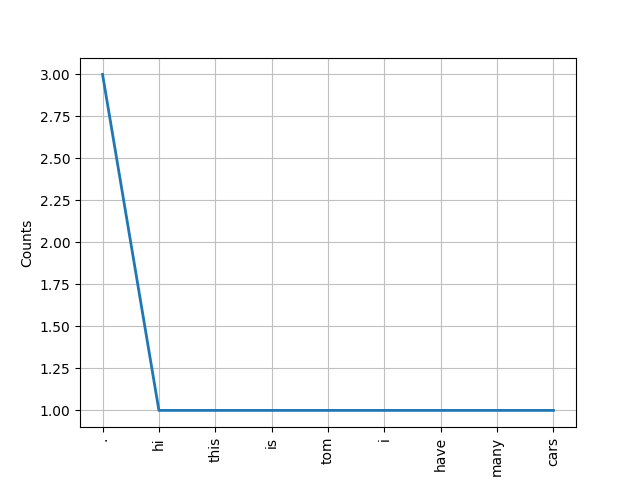
text.plot(9)
print(text.count('.'))
print(text.count('many'))
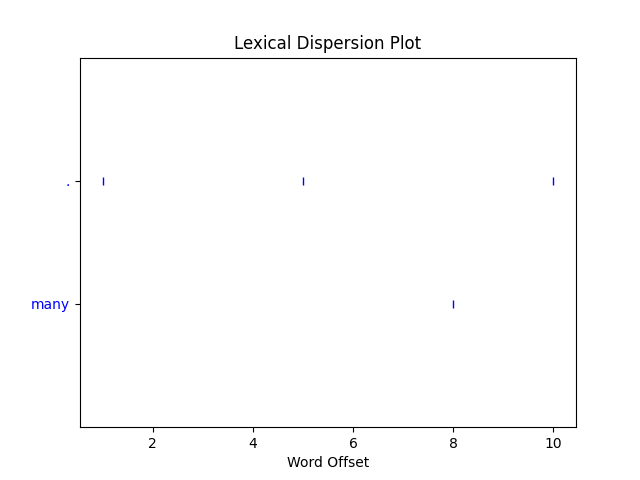
text.dispersion_plot(['.', 'many'])
# 위치표시, 산포도['hi', '.', 'this', 'is', 'tom', '.', 'i', 'have', 'many', 'cars', '.']
<Text: hi . this is tom . i have...>
11
9
. 3
hi 1
this 1
is 1
tom 1
i 1
have 1
many 1
cars 1
3
1
stopword 제거, stemming 형태소 분석
# stopwords: the of and 등 분석에 필요없는 단어
# stemming 형태소 분석
import nltk
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
sentence = "Hi . This is Tom . I have many cars ."
sentence = sentence.lower()
tokens = nltk.word_tokenize(sentence)
stop = set(stopwords.words('english'))
# stopwords load
tokens = [t for t in tokens if t not in stop]
# stopwords 에 없는것만 저장
print(tokens)
print('this' in stop)
porter_stemmer = PorterStemmer()
tokens = [porter_stemmer.stem(token) for token in tokens]
# stemmer 로 형태소 분석 ex clos-( closing, closed, closely)
print(tokens)['hi', '.', 'tom', '.', 'many', 'cars', '.']
True
['hi', '.', 'tom', '.', 'mani', 'car', '.']
연습문제
주어진 3문장 간에 유사도를 구하세요.
1. pre-processing (tokenize, stopwords 제거, stemming)
2. Cosine similarity 함수 구현
3. Doc-word matrix 만들기 (단어 사전 구축, numpy로 벡터화)
4. Similarity 구하기 (doc1&doc2:0, doc1&doc3:0, doc2&doc3: x)
doc1 = "Rafael Nadal Parera is tennis player."
doc2 = "Donald Trump is president."
doc3 = "Donald Trump has yellow hair."
import numpy as np
import nltk
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
def pre_processing(doc, stop, stem):
doc = doc.lower()
tokens = nltk.word_tokenize(doc)
tokens = [t for t in tokens if t not in stop]
tokens = [stem.stem(token) for token in tokens]
return tokens
def get_sim(A, B):
s1 = np.dot(A, B)
s2 = np.sqrt(np.sum(A * A))
s3 = np.sqrt(np.sum(B * B))
return s1 / (s2 * s3)
def doc_word_matrix(text, dictionary):
vec = []
for token in dictionary:
vec.append(text.vocab()[token])
doc_vec = np.array(vec)
return doc_vec
stop = set(stopwords.words('english'))
stem = PorterStemmer()
doc1 = "Rafael Nadal Parera is tennis player."
doc2 = "Donald Trump is president."
doc3 = "Donald Trump has yellow hair."
tokens_1 = pre_processing(doc1, stop, stem)
tokens_2 = pre_processing(doc2, stop, stem)
tokens_3 = pre_processing(doc3, stop, stem)
dictionary = list(set(tokens_1 + tokens_2 + tokens_3))
text_1 = nltk.Text(tokens_1)
text_2 = nltk.Text(tokens_2)
text_3 = nltk.Text(tokens_3)
doc_vec_1 = doc_word_matrix(text_1, dictionary)
doc_vec_2 = doc_word_matrix(text_2, dictionary)
doc_vec_3 = doc_word_matrix(text_3, dictionary)
print("sim of doc1 & doc2:")
print(get_sim(doc_vec_1, doc_vec_2))
print("sim of doc1 & doc3:")
print(get_sim(doc_vec_1, doc_vec_3))
print("sim of doc2 & doc3:")
print(get_sim(doc_vec_2, doc_vec_3))sim of doc1 & doc2:
0.20412414523193154
sim of doc1 & doc3:
0.18257418583505536
sim of doc2 & doc3:
0.6708203932499369
'파이썬 딥러닝 ai 스쿨 기초 > lecture07' 카테고리의 다른 글
| lecture07 1교시 개념정리 CNN 기반 텍스트 분류 (0) | 2021.03.26 |
|---|